
안녕하세요💖
팀 영상 제작을 마무리하고
이번 포스팅부터
6주간 개인 분석 프로젝트를
진행하게 되었어요!

혼자서 데이터 분석 프로젝트를
진행해 보는 게
처음이라 설렘 반 걱정 반이지만
열심히 해보겠습니다😆
✏️주제 선정 및 배경
시작이 반이라고 했던가요ㅎㅎ
주제 선정에 꽤 많은 시간이 걸렸는데요!
제가 선택한 주제는✨
.
.
.
바로!
시계열 분석을 활용한
"서울시 112 신고 접수량 예측'입니다.
+) 시계열 분석을 통한 모델링을 진행하지만
시각화를 통해서 신고 접수량에
영향을 미치는 다른 요소들도
살펴볼 예정입니다!
주제 선정 이유가
궁금하시다구요~?🙃
제가 유튜브 알고리즘에 이끌려
EBS에서 하는 "사선에서"라는
다큐멘터리를 본 적이 있는데요!
경찰분🚔들이 교대 근무를 하시는
모습을 보면서
정말 대단하시다는 생각을 한 적이 있어요!
그리고 기사들을 보면,
"경찰 인력 부족 문제"에
대해서 다루는 경우도 많죠
아시아 경제 기사에 따르면,
서울 지역 내 지구대·파출소 242곳을 전수조사한 결과,
전체 242곳 중 105곳(43.4%)이 정원 미달
이라는 점도 알 수 있습니다!
경찰 업무는 치안과 밀접한
관련이 있기 때문에
이를 조금이라도 해결할 수 있는
방안을 찾아보고자 하였습니다.
그래서 데이터 셋을 기반으로.
경찰의 현장대응시간 단축하고
탄력적인 순찰이 가능하도록 할 수 있도록 하는
분석 프로젝트를 진행해 보면 좋겠다는
생각을 해보았습니다!
(아주 TMI 지만 어렸을 적 프로파일러가
꿈이었던 저는 이번 프로젝트가 아주 두근두근합니다😆)
👩🏻💻데이터 셋 선정
제가 사용할 데이터 셋은 총 3가지입니다!
1. 전국 112 신고 접수 데이터 (2019~2021년)
https://www.bigdata-policing.kr/product/view?product_id=PRDT_19
아래는 각 열에 대한 설명입니다!
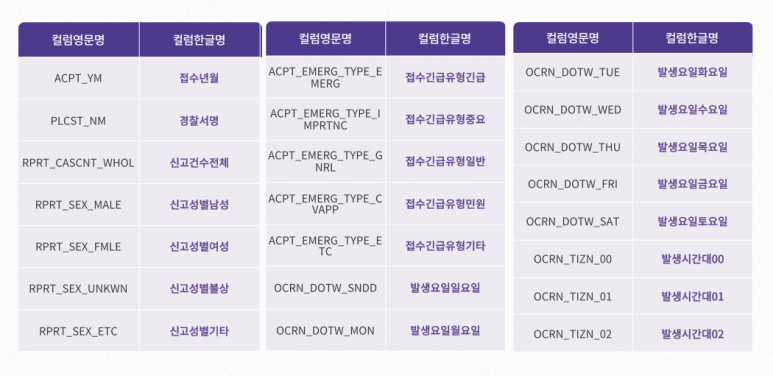
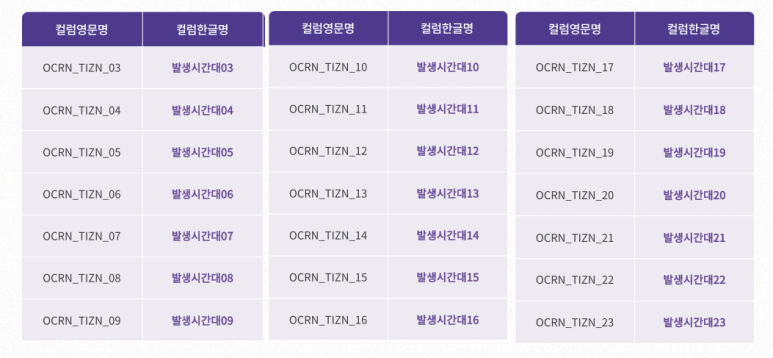
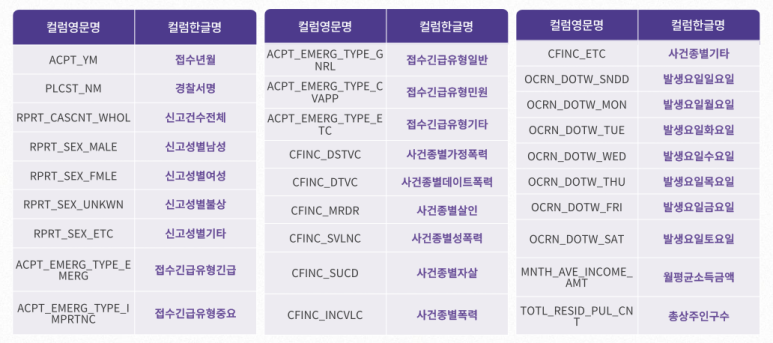
2. 112 신고 영향요소 융합 데이터 (2019~2021년)
https://www.bigdata-policing.kr/product/view?product_id=PRDT_138
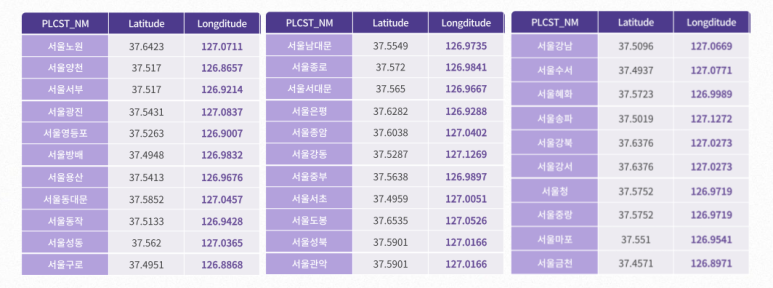
3. 서울 지역의 경찰서 위도 & 경도 데이터
이 데이터는..!
구글맵🧭을 활용해
총 32개의 경찰서 위도& 경도를
한땀한땀 정리하여
사용했습니다!
전처리를 해보자~✨
전처리의 전체적인 프로세스는
다음과 같습니다!
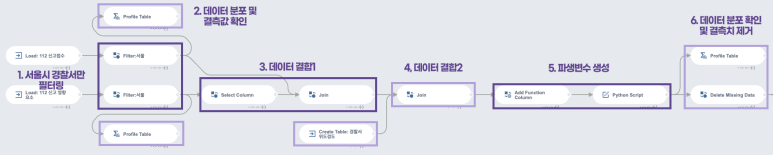
순서대로 한 번 과정을
살펴보겠습니다!
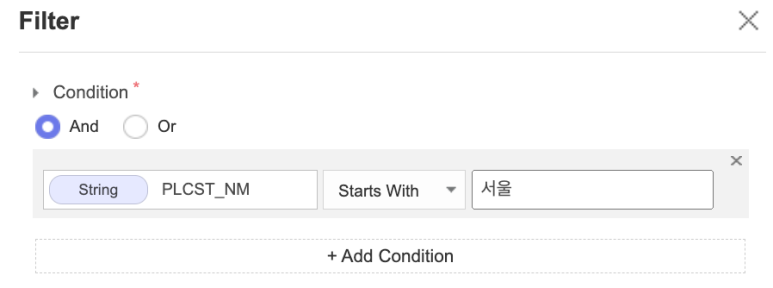
1. 서울시 경찰서만 필터링
112 신고 접수 & 112 신고 접수 영향요소
데이터는 전국에 있는 경찰서 접수 현황을 나타내고
있습니다!
저는 자료를 조금 더 정확하고 집중적으로
보기 위하여
"서울"로 시작하는 경찰서들만
필터링하여 데이터를 사용하였습니다.
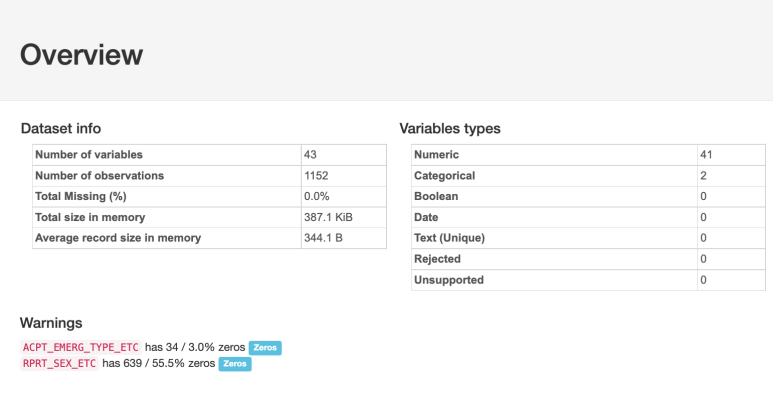
2. 데이터 분포 및 결측치 확인
112 신고 접수 데이터의 경우에는
결측치가 없음을 확인할 수 있네요!
112 신고 영향요소 데이터의 경우에는
결측치가 0.1% 존재함을 확인할 수 있네요!
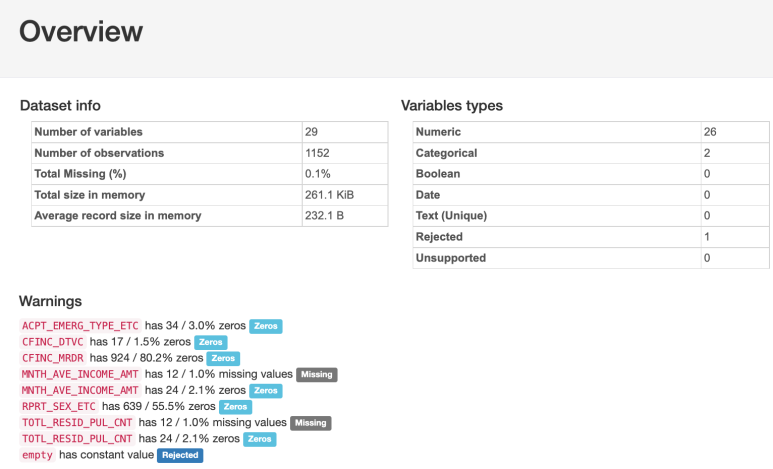
원래는 결측치를 바로 제거할 수 있지만,
두 개의 데이터를 합치기 위해서
뒤 쪽에 진행하였습니다!
3. 데이터 결합 1
위에서 데이터 셋의 각 열을
설명드린 거 기억하시죠?ㅎㅎ
겹치는 열이 있기 때문에
Join 함수를 활용해서
데이터를 결합해 주었는데요!
그전에 112 신고 영향요소 데이터에
결측치가 있었기 때문에
Join 함수만 사용하면 행 개수가 안 맞더라고요!
그래서 Select Column 함수로
데이터에서 필요한 열만 선택하여
Join 함수를 사용하였습니다!
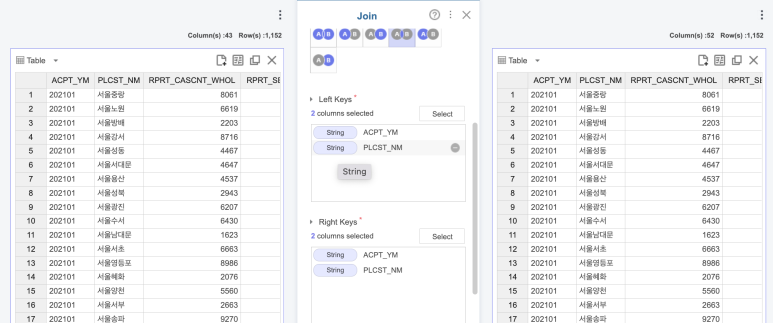
짜잔✨
52개의 열을 갖는
1152행의 데이터가 되었네요!
4. 데이터 결합 2
이번에는 결합한 데이터에
각 경찰서의 위도&경도 데이터를
넣어줄거에요!
이번에도 역시 Join 함수를
활용하였습니다!
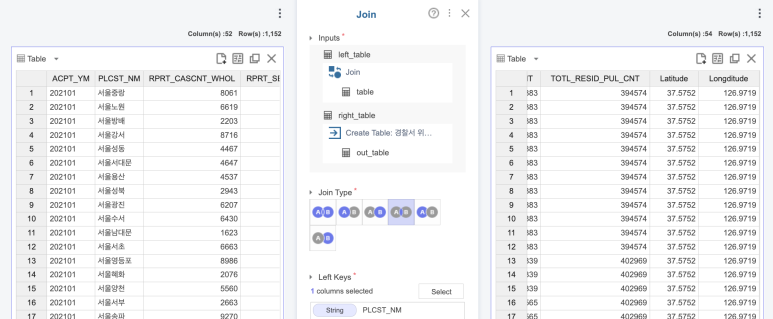
2개의 열이 늘어난 거 보이시죠~?
5. 파생 변수 생성
파생 변수를 생성하는 방법은
2가지 정도가 있습니다!
일단 첫 번째는
Add Function Column나
Add Function Columns 함수를
사용하는 것인데요!
저는 경찰서 별로
신고 접수 전체량/총 상주인구수를
구하고 싶어서
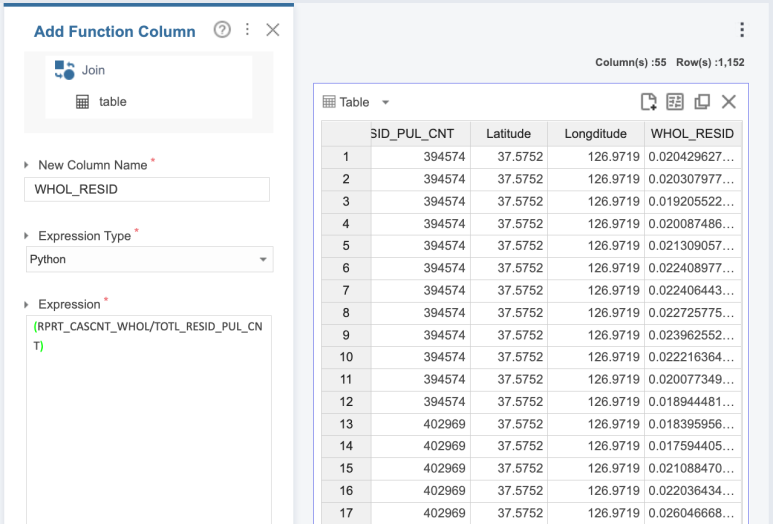
이렇게 진행하였습니다!
두 번째로는 Python Script 함수를
사용하였는데요!
접수 연월 열을
년과 월로 나눈 두 가지 열로
변환하고 싶어서
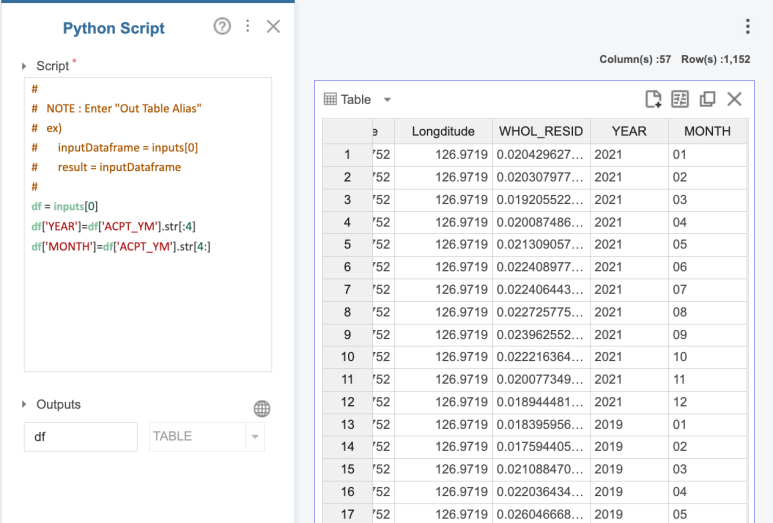
위와 같이 진행하였습니다!
6. 데이터 분포 확인 및 결측치 제거
이제 마지막으로
Profile Table로 전반적인
분포를 확인하였습니다!

아까도 발견했던
결측치를 제거하기 위하여
Delete Missing Data 함수를
사용하였어요!
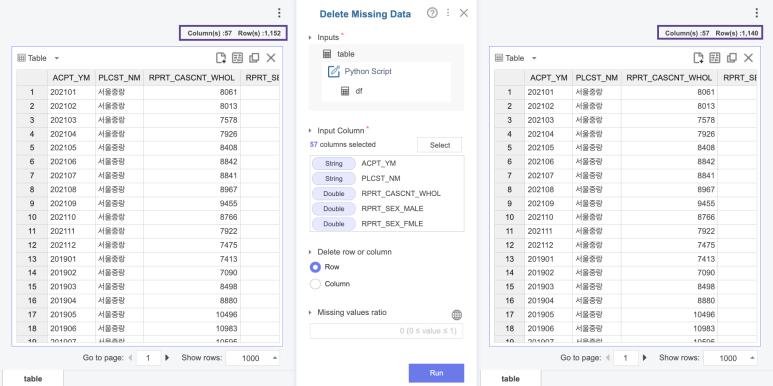
다음과 같이
총 12개의 행이 지워졌습니다!💖
이렇게 기본적인 전처리 과정이 끝이 났네요!
🗓포스팅 계획 & 이런저런 이야기
지금 제 계획🗓은
2주 차-시각화(1)
3주 차-시각화(2)
4주 차-시계열 분석 by Month(1)
5주 차-시계열분석 by Time(2)
6주 차-시계열 분석 with 평가(3) & 결과
다음과 같습니다!
참고해 주시면 좋을 것 같아요!
+) 서울시 지도를 활용해서
Brightics로 시각화해보는
것도 준비 중이니까 기대해 주세요~!

TMI를 조금 시작하자면
사실 시계열 분석에 대해서
모르는 점이 많지만
더 공부해 보고 싶어서
이 데이터를 선택하였는데요!
부족한 부분이 많겠지만
시도해 봐야
얻어 가는 것들이 많으니까
도전해 보려고 합니다!!
책과 레퍼런스들을 활용해서
공부하고
멘토님께도 모르는 부분을
여쭤보면서 진행해봐야겠어요ㅎㅎ
이야기가 약간 중구난방이지만
워낙 데이터가 크다 보니
case 별로 정리된 게 아니라
연도와 월별로 count 되어 있어서
더 많은 모델링을 활용하기에
어렵다는 점이 조금 아쉽네요 ㅠㅠ
(회귀나 군집화 등등도 사용할 수 있으면
더 좋을 텐데!😊)
긴 글 읽어주셔서 감사합니다~~
다음 주에 봐요!
안녕

※ 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
#삼성SDSBrightics #BrighticsStudio #브라이틱스 #모델링 #데이터분석
#Brightics서포터즈 #브라이틱스서포터즈 #데이터시각화 #EDA #시계열



