
안녕하세요!
여러분은 쇼핑할 때 어떤 것을
자주 구매하시나요?

저 같은 경우에는
커피 & 옷 & 화장품이
저의 통장을 텅장으로 만들어버리죠...ㅎㅎ
사실 구매목록이라는 건
관심사에 따라 소비자별로
차이가 있잖아요!
그렇다면 기업의 경우에는
소비자의 특성을 파악해서
물품 별로 타깃을 정확히 설정하는 게 좋겠죠?
그래서 이번 포스팅에서는
K-means 군집화 알고리즘을 활용하여
Customer Personality Analysis 데이터를
분석해보겠습니당~

먼저, 데이터는 다음 링크에서
다운로드하실 수 있습니다!
↓↓↓
Customer Personality Analysis 데이터
브라이틱스 스튜디오를 켜고 데이터를 로드해보면
매우 많은 열들이 나오죠! ㅎㅎ

무려 30개!!
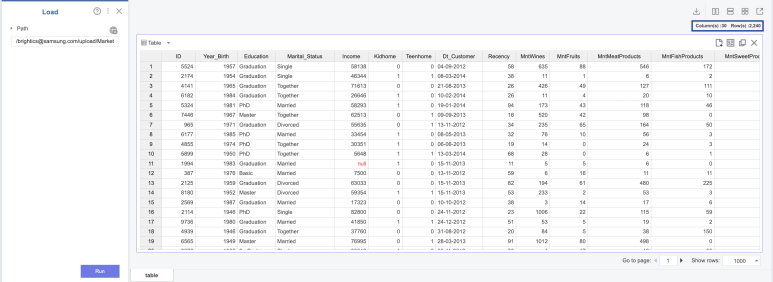
(네..저도 당황스럽네요 ㅎㅎ)
이제 아래와 같이
데이터의 features을 간단히 살펴보았습니다!


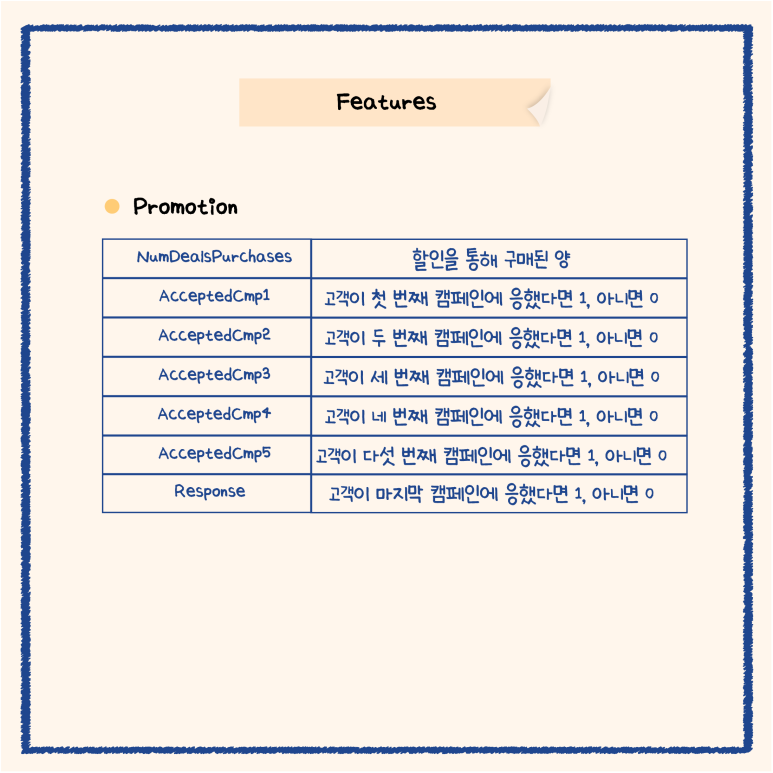

자 이제 Data Cleaning 과정을 거칠 건데요!

위와 같은 과정들을 통해
Modeling에 적합한 데이터로 변형할 예정입니다!
📍결측값 처리
먼저 Profile Table 함수를 활용하여
결측값이 존재하는지 확인해보았습니다!
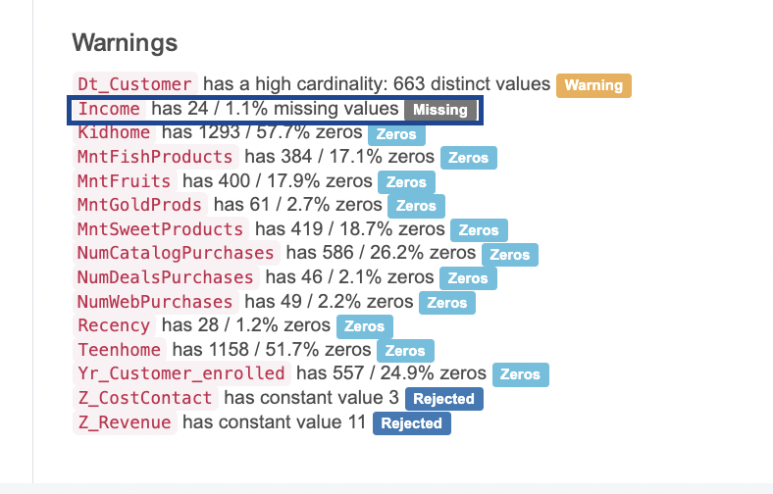
그 결과 Income 열에서 24개의 결측값이 발견되었어요!
그래서 Replace Missing Number 함수로
결측값을 중앙값(Median)으로 대체하였습니다~
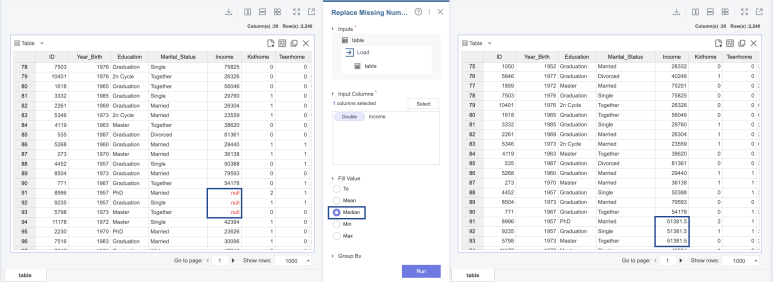
📍파생 변수 생성
이제 Add Function Columns 함수를 사용하여
파생 변수를 만들어볼 차례인데요!
아래와 같이 데이터를 효율적으로 사용할 수 있도록
파생 변수를 만들어보았습니다!
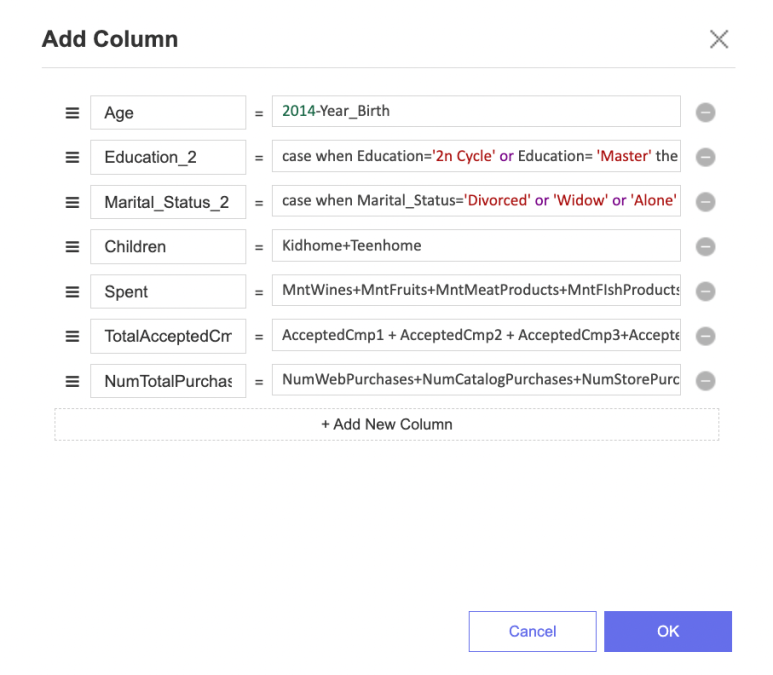
(+참고로 이 함수에서는 Expression Type이 SQLite 형태만 지원합니다!)
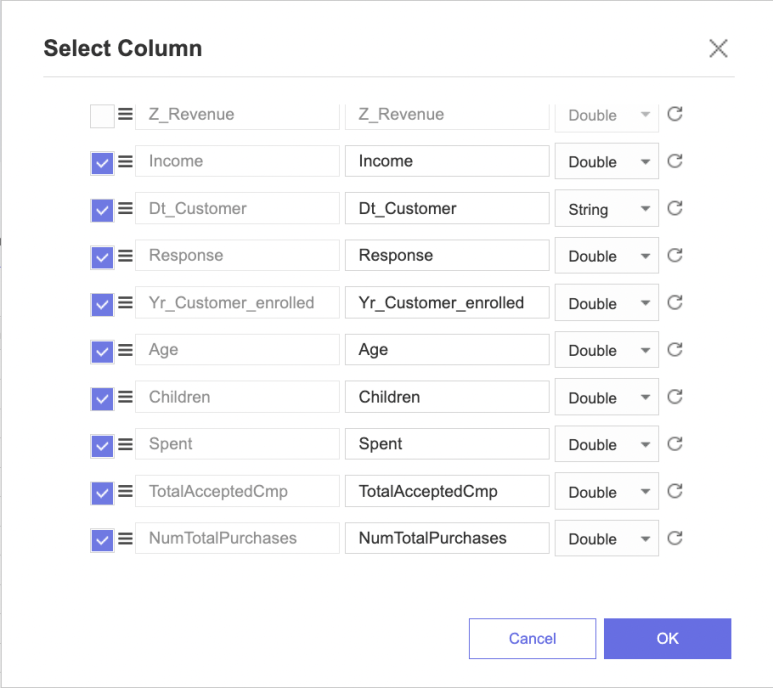
그다음에 추가한 파생 변수를 토대로
Select Column 함수를 활용하여
필요한 열들만 선택하였습니다!
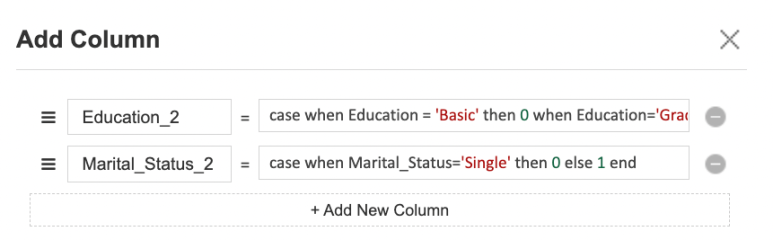
그 후 다시 Add Function Columns 함수를 활용하여
Education과 Marital_Status를 숫자형 데이터로 변경하였습니다!
Education의 경우
Basic=0, Graduate=1, Master=2, PhD=3가 되도록 변형하였고,
Marital_Status의 경우
Single=0, Together=1이 되도록 변형하였습니다!
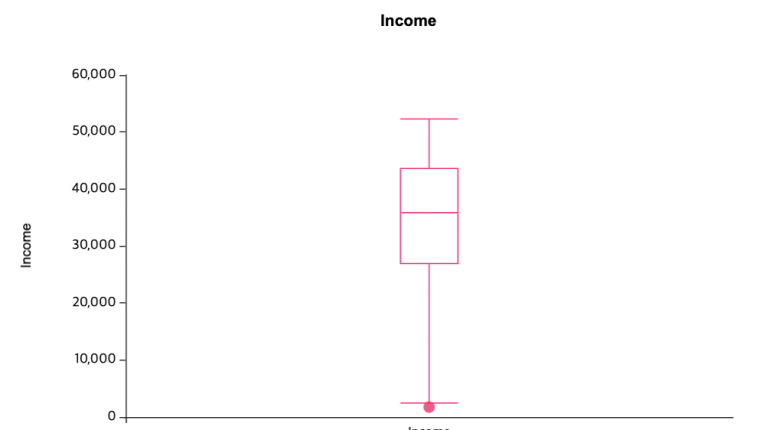
📍이상값 처리
이번에는 age와 income의 box plot을 통해서
이상값을 처리하려고 합니다!
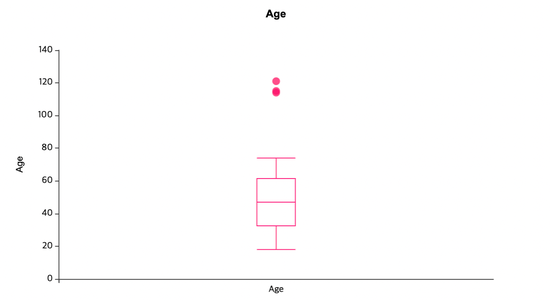
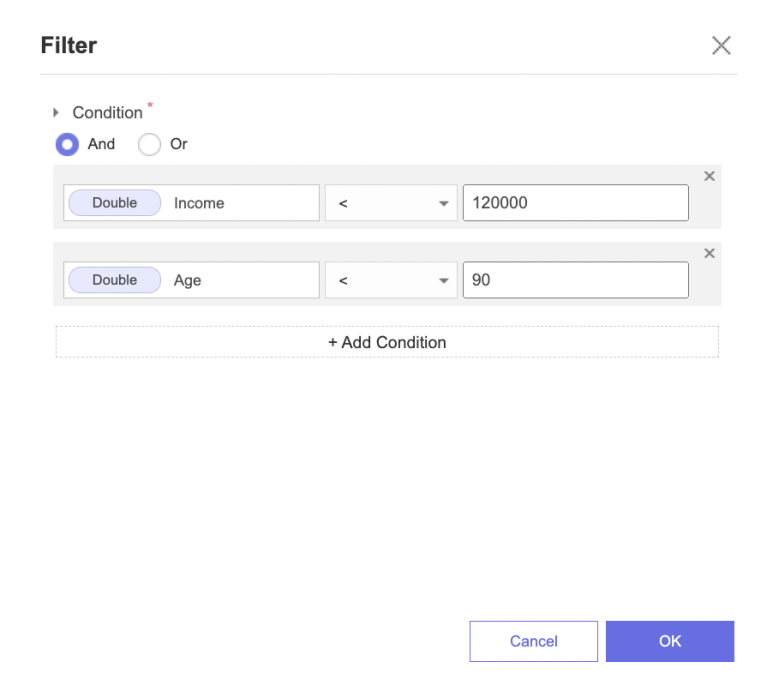
Filter 함수를 통해서
Income은 120000 미만이고,
Age는 90 미만이 되도록 하였습니다~✨
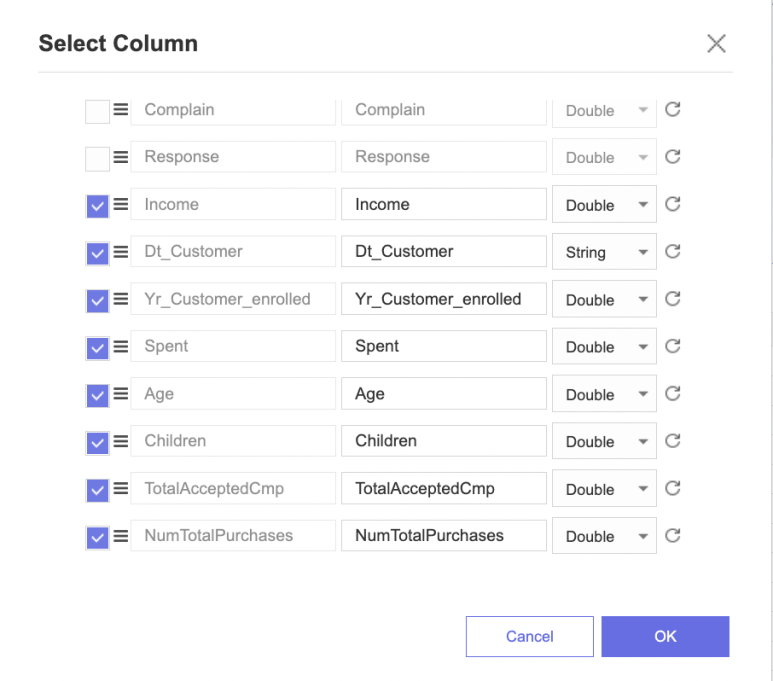
그다음에는 Select Column을 사용하여
아까와 같이 열 이름을 간단하게 수정하고,
사용할 열들만 선택하였습니다~
휴~~!

드디어 Data Cleaning이 끝났네요~~
Yeah~~

여기서부터는 아래와 같은 과정을 거칠 건데요!
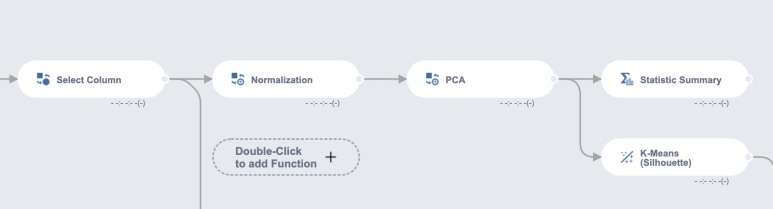
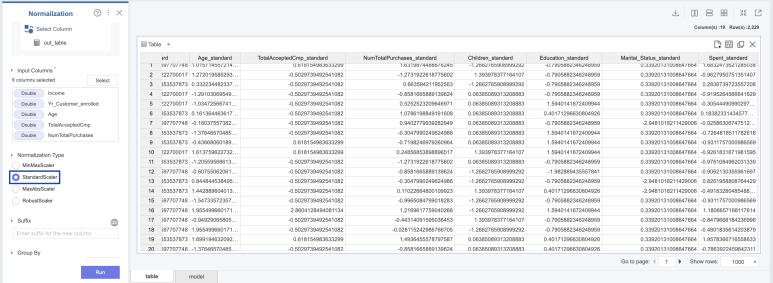
📍Normalization
각 열이 단위가 다 다르기 때문에
Normalization 함수의 StandardScaler를
활용하여 표준화하였습니다!
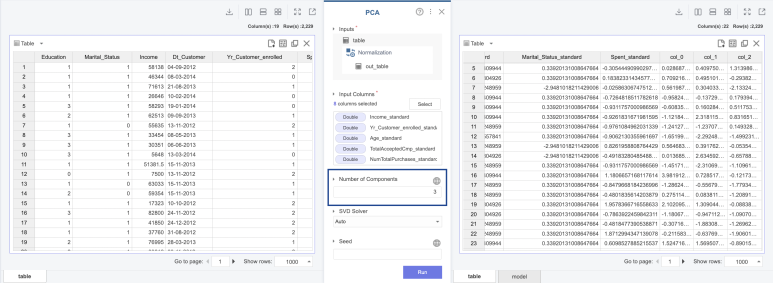
📍PCA
그다음에는 차원을 축소해보도록 할게요!
저는 Number of Components를 3으로 설정하였습니다!
📍K-Means (Silhouette)
이제 대망의 K-Means 군집화 알고리즘을
사용할 차례인데요~

K-Means 군집화와 실루엣 계수에 대하여
조금 더 자세히 알아보도록 합시다~
먼저 "군집화"라는 것은
비슷한 속성을 가진 데이터들끼리 묶는 것을
의미하는데요!
그중에서도 K-Means 군집화 알고리즘은
각 데이터로부터 그 데이터가 속한 클러스터의 중심까지의 평균거리를
최소화하는 것을 목표로 합니다!
실루엣 계수는 아래 설명을 참고해주세요~

자! 이제 직접 K-Means 함수를 활용하여
군집화를 해보겠습니다~
저는 차원 축소를 한 데이터들을 활용하여
Number of Clusters Set이 2, 3, 4,5 ,6일 때의
결과를 얻어보았어요~
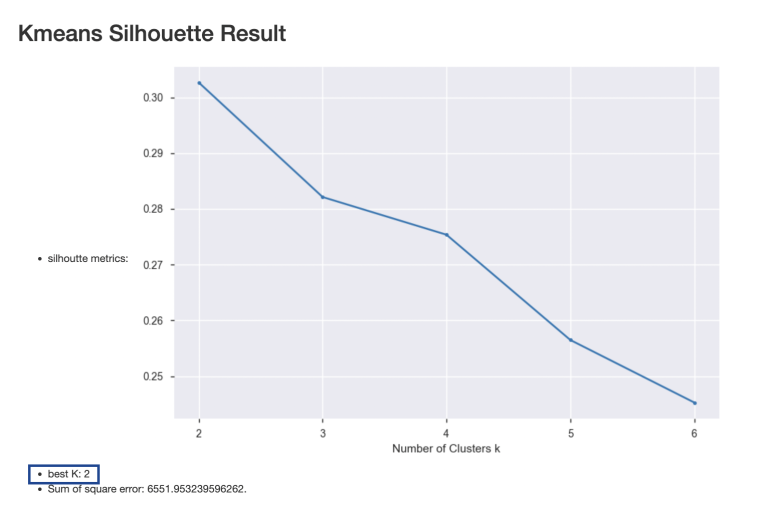
짜잔✨
최적의 군집화 개수는 2개로 나타났어요~
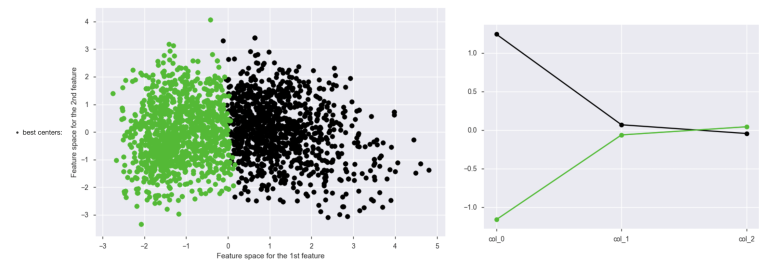
왼쪽 그래프는 군집들이 모여있는 점을 표현한 것이고,
오른쪽 그래프는 군집별 실루엣 계수를 나타낸 것입니다!

이제 군집화된 결과를 토대로
보고서를 작성하고 Insight를 도출해보았어요!
Brightics Studio의 Report 기능을 사용하면
이렇게 시각화된 결과들을 정리하고,
pdf로 저장도 가능하답니다!
(최고최고!!👍🏻)

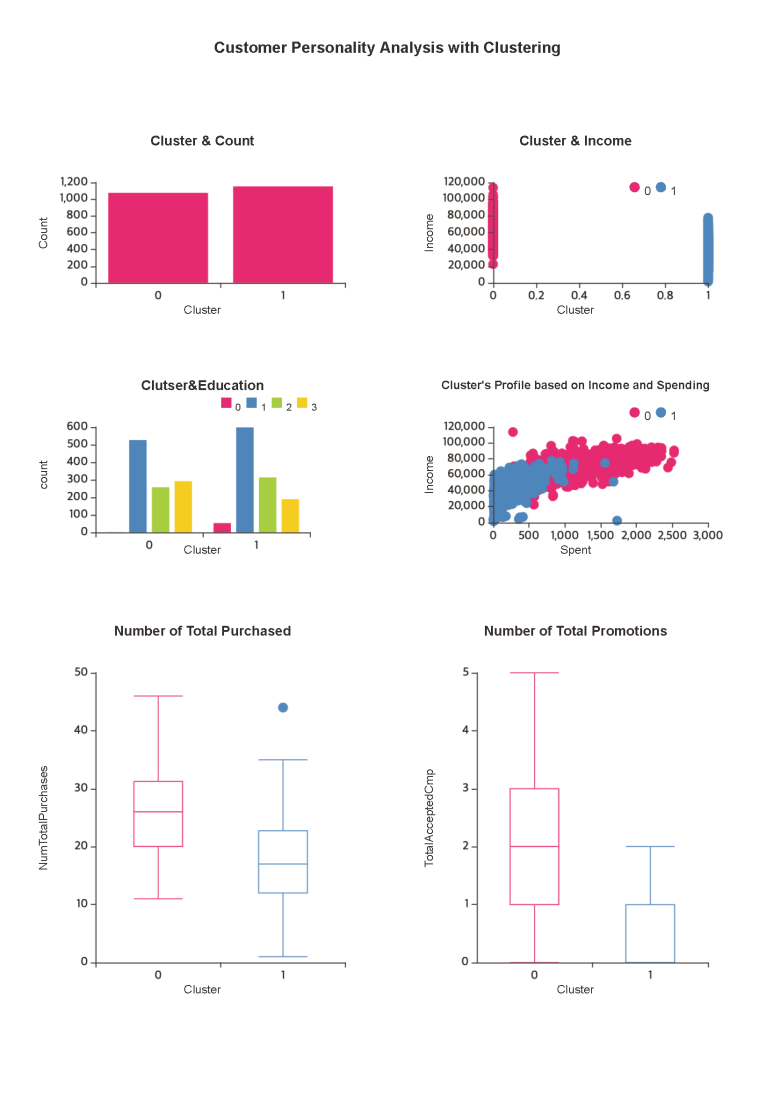
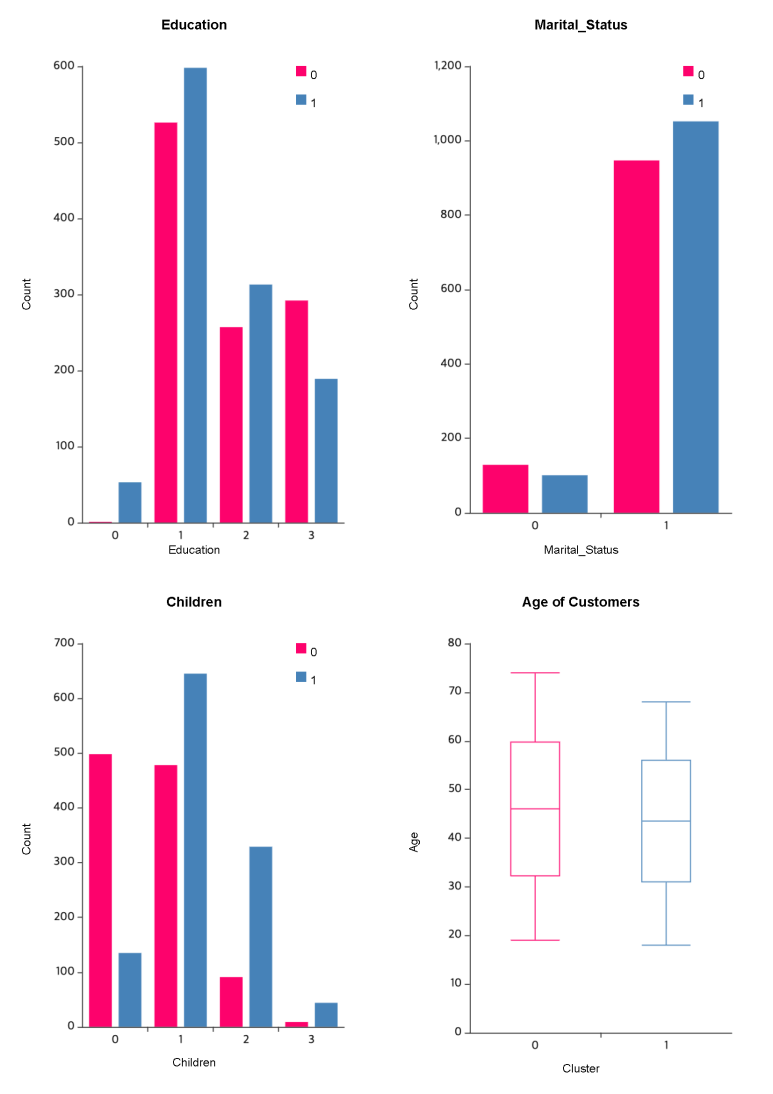
결과를 종합해보면~~
먼저, Cluster 0과 Cluster 1는 공통적으로
고객의 연령대가 골고루 퍼져있네요!
📍Cluster 0은 소비와 지출이 둘 다 많은 편입니다!
또한, 대부분 가정에 아이가 없거나 1명이며
부모가 아닐 확률이 높습니다.
📍Cluster 1은 소비와 지출이 둘 다 적은 편입니다!
대부분 가정에 1명 이상의 아이가 있으며
부모일 확률이 높습니다.
이렇게 군집화를 활용한 고객 특성 분석 프로젝트가
끝이 났습니다~~!

긴 포스팅 읽어주셔서 감사합니다!
다음 포스팅도 알차게 데리고 올게요~~
안녕!!

※ 본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
#삼성SDSBrightics #BrighticsStudio #브라이틱스 #모델링 #데이터분석
#Brightics서포터즈 #브라이틱스서포터즈 #군집화 #군집화알고리즘 #K-Means
'Brightics 서포터즈 3기' 카테고리의 다른 글
| 삼성 SDS Brightics_팀 분석 프로젝트(2)] 06. 개인 의료비🏥 예측 프로젝트✨ (피어슨 vs. 스피어만 상관계수) (0) | 2022.08.22 |
|---|---|
| [삼성 SDS Brightics_팀 분석 프로젝트(1)] 05.개인 의료비🏥 예측 프로젝트✨ (0) | 2022.08.16 |
| [삼성 SDS Brightics_개인 분석 프로젝트(2)] 03.비행기✈️ 가격 예측 모델링 with 다중선형회귀✨ (0) | 2022.07.02 |
| [삼성 SDS Brightics_개인 분석 프로젝트(1)] 02-2.비행기✈️ 가격 예측 데이터 EDA (0) | 2022.06.28 |
| [삼성 SDS Brightics] 02-1.기다리고 기다리던!!✨Brightics 서포터즈 3기 ✨발대식 후기😘 (0) | 2022.06.26 |



